La certezza dei dati trasmessi è garantita da un tracciato record condiviso, nel quale vengono definite le posizioni esatte dei dati, il loro formato, le codifiche e le regole di scrittura e di lettura di ogni campo. La Figura 1 mostra un esempio di tracciato record anagrafico (ovviamente è un tracciato ridotto per motivi di spazio).
Figura 1 – Esempio di tracciato record anagrafico
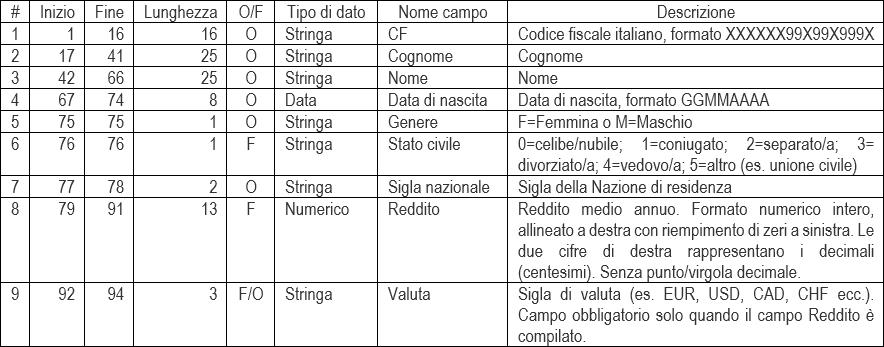
Il tracciato definisce campi con tipi di dati diversi, in modo da fare un esempio abbastanza concreto. Alcuni campi sono definiti come Obbligatori oppure Facoltativi, oppure entrambi (F/O): come specificato nella descrizione, il campo Valuta è obbligatorio solo se è compilato il campo Reddito. Utilizzando la terminologia anglosassone, talvolta il campo O/F viene invece definito R/O, cioè Required oppure Optional.
Il campo Reddito è definito come numero intero, ma nella descrizione è specificato che le due cifre più a destra sono i decimali che servono a tenere conto dei centesimi. La scelta di non prevedere il punto o la virgola decimale è funzionale al fatto che questo simbolo potrebbe essere frainteso, perché nei Paesi di lingua anglosassone si usa il punto, in altri paesi (come in Europa) si usa la virgola. Chiaramente in fase di scrittura bisogna togliere il carattere separatore dei decimali, mentre in fase di lettura bisogna aggiungerlo: ne consegue che dovranno essere definiti due metodi che si occupano di queste operazioni.
Nella Figura 2 potete vedere un esempio popolato con alcuni record, secondo il tracciato che abbiamo appena definito (ho aggiunto delle righe rosse verticali per distinguere meglio i vari campi).
Figura 2 – Esempio di dati corrispondenti al tracciato record

La figura ci dà alcune informazioni aggiuntive molto utili:
- non c’è una riga di intestazione con i nomi dei campi come invece c’è nei file CSV;
- ogni riga viene terminata da una coppia di caratteri CR+LF (carriage return e line feed, cioè rispettivamente i caratteri ASCII 13 e 10) che servono per il “ritorno a capo”. Attenzione che alcuni sistemi (per esempio UNIX) utilizzano solo LF come terminatore di riga e quindi potrebbero causare dei problemi leggendo la riga da un programma in Windows. Sicuramente nel conteggio della lunghezza di ogni riga (completa di terminatori) potrebbe esserci la differenza di un carattere;
- i campi in formato “testo” molto grandi vengono riempiti di spazi e questo può comportare lo spreco di molto spazio, ma questo svantaggio viene compensato in fase di archiviazione dei file compressi;
- per quanto riguarda il campo “Reddito”, potete vedere che solo alcune righe contengono un valore numerico allineato a destra e riempito con zeri a sinistra, gli altri sono vuoti. Qui bisogna verificare se il destinatario dei dati vuole che vengano compilati anche i campi vuoti con zeri di riempimento oppure se consente di non indicare alcun valore, visto che è un campo facoltativo. Dal punto di vista concettuale, un valore “Reddito” a zero è molto differente da un valore non indicato: nel primo caso stiamo dicendo che il suo reddito è nullo, cioè sappiamo che non guadagna nulla; nel secondo caso stiamo dicendo che non sappiamo quanto guadagna;
- la lunghezza del file diviso il numero di righe contenute nel file dà per risultato la lunghezza del record (compresi uno o due caratteri terminatori di riga). Viceversa, se dividiamo la lunghezza del file per la lunghezza del record (più uno o due caratteri terminatori di riga) possiamo sapere quanti record sono contenuti nel file senza doverlo leggere.
Con tutte queste informazioni potremmo agevolmente creare un programma per scrivere e leggere i dati in questo formato, ma perché dovremmo reinventare l’acqua calda?
Vi mostreremo, invece, una libreria che fa al caso nostro per risparmiare molto tempo e per fare le cose nel modo giusto.
Conclusione
Ora che abbiamo definito il contesto del problema, nella terza e ultima parte vedremo come questo problema può essere risolto in modo estremamente semplice ed elegante con la libreria open-source di nome FileHelpers.