Buonasera a tutti.
Vi scrivo per chiedere lumi alla community su un algoritmo che dovrei implementare, per rendere più semplice una parte del mio lavoro.
Cercherò di descrivere con dovizia di dettagli i presupposti, per cercare di rendere il più chiare possibili le mie richieste.
Dunque, alla fine di ogni mese, il mio responsabile sul mio luogo di lavoro mi consegna, tramite posta elettronica aziendale, le letture delle mie timbrature in ufficio relative al mese appena trascorso.
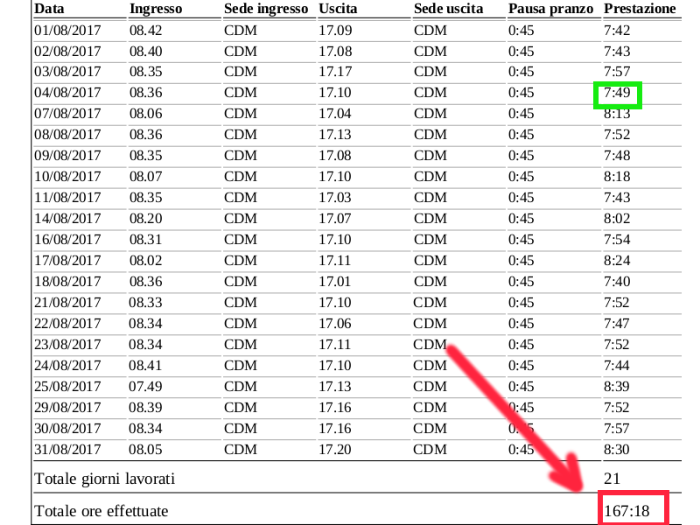
Queste letture compaiono secondo il file che vi allego quì sotto.
I dati che mi interessano sono i vari record che identificano nel dettaglio ogni giorno, tutte le ore che ho lavorato e, il dato più importante è quello che si trova in calce al modulo, che riporta il numero complessivo di ore lavorate relative a quel particolare mese.
Nel modulo che ho allegato qui come esempio, ho lavorato nel mese 167 ore e 18 minuti.
Ora, nel database aziendale devo registrare il computo delle ore definitivo per ogni mese, ma questo sistema ha una particolarità molto fastidiosa, perchè ammette per ogni giornata lavorata come orario lavorabile solamente una cifra intera, ovvero in questo sistema posso selezionare, per ogni giorno o 7 ore, oppure 7.30 ore oppure 8 ore, oppure 8.30 e così via.
Questo significa che io, ogni mese, devo cambiare a mano le mie timbrature inserendo per ogni giornata solo uno di questi possibili valori, ma facendo in modo che il computo complessivo delle ore non sia eccessivamente lontanop da quello che compare sul report ufficiale.
In pratica, devo aggiustare ogni giornata lavorativa segnando quando 7.30 ore, quando 8, ma facendo in modo che la somma di tutte queste sia il più possibile prossima alla lettura ufficiale.
Tutto questo, fatto a mano mi porta via molto tempo, e quindi vorrei sapere se c'è un metodo per calcolare e distribuire in maniera automatica tutti questi margini in maniera tale che, alla fine la risultante sia il più possibile prossima.
Di solito, ordinare le varie letture in maniera ascendente o discendente, non mi crea problemi, ma cerco aiuto per quanto riguarda l'implementazione, almeno logica dell'algoritmo.
In quale maniera posso calcolare, come distribuire le varie quantità marginali, in modo da ottenere un computo risultante idoneo?
Spero che la richiesta sia abbastanza chiara.
Vi ringrazio per la disponibilità.
Saluti.
Allegati:
 18557_af710206aaac395d3d2f26af8cd70f7b.png
18557_af710206aaac395d3d2f26af8cd70f7b.png