import os
import sys
import logging
import gym
import ray
import traci
import traci.constants as tc
import sumolib
import random
from ray.rllib.algorithms import ppo
import matplotlib.pyplot as plt
# Importazione della libreria SUMO
if 'SUMO_HOME' in os.environ:
sys.path.append(os.path.join(os.environ['SUMO_HOME'], 'tools'))
else:
sys.exit("Please declare environment variable 'SUMO_HOME'")
# Configurazione del logger
logger = logging.getLogger(__name__)
# Impostazioni di SUMO e del percorso di scenario
sumoBinary = os.path.join(os.environ['SUMO_HOME'], 'bin', 'sumo-gui.exe')
sumoCmd = [sumoBinary, "-c", os.path.join("Mappacanosa.sumocfg")]
sumoNet = sumolib.net.readNet(os.path.join("Mappacanosa.net.xml"))
baseRoute = "r_0"
edges = {"E_0": 0}
startEdge = "E_0"
revStartEdge = "-E_0"
endEdge = "E1"
class RoutePlanner(gym.Env):
ego_idx = -1
current_ego = "EGO_0"
optimalRoute = [startEdge]
edges = []
prev_dist = 0
destination_reached_count = 0 # Contatore per il raggiungimento della destinazione
def __init__(self, env_config):
traci.start(sumoCmd)
self.edges = traci.edge.getIDList()
self.action_space = gym.spaces.Discrete(3)
self.observation_space = gym.spaces.Discrete(len(self.edges))
self.addVehicle()
self.addRandomTraffic()
def reset(self):
return edges["E_0"]
def step(self, action):
prev_current_road = ""
action_applied = False
reward = 0
threshold_distance = 10
distance = 0 # Variabile distanza inizializzata con un valore predefinito
current_road= ""
while True:
traci.simulationStep()
ego_values = traci.vehicle.getSubscriptionResults(self.current_ego)
if tc.VAR_ROAD_ID in ego_values:
current_road = ego_values[tc.VAR_ROAD_ID]
done = ego_values[tc.VAR_ROAD_ID] == endEdge or ego_values[tc.VAR_ROAD_ID] == revStartEdge
if done:
if ego_values[tc.VAR_ROAD_ID] == endEdge:
reward = 10000 # Reward quando il veicolo arriva a destinazione
RoutePlanner.destination_reached_count += 1 # Incremento il conteggio del raggiungimento della destinazione
#print('Arrivato a destinazione')
else:
done = True
if done:
self.addVehicle()
break
if ego_values[tc.VAR_ROAD_ID] == revStartEdge:
reward = -2 # Penalità se il veicolo si muove all'indietro
else:
done = True
# Controllo se c'è un veicolo davanti al veicolo corrente
leading_vehicle = traci.vehicle.getLeader(self.current_ego)
if leading_vehicle is not None:
# Ottengo la distanza tra il veicolo corrente e il veicolo davanti
distance = leading_vehicle[1]
# Se la distanza è inferiore a un certo valore di soglia, assegno una ricompensa negativa
if distance < threshold_distance:
reward = -2
if prev_current_road == "":
prev_current_road = current_road
if current_road != prev_current_road:
# Controllo se il veicolo si trova su una strada con un semaforo
if current_road == "light":
reward = -1 # Penalità per la presenza di un semaforo
# Controllo se viene effettuata una svolta
if current_road == "junction":
reward = -1 # Penalità per effettuare una svolta
break
elif not action_applied:
outEdges = {}
try:
outEdges = sumoNet.getEdge(ego_values[tc.VAR_ROAD_ID]).getOutgoing()
except Exception:
pass
outEdgesList = []
for outEdge in outEdges:
outEdgesList.append(outEdge.getID())
if len(outEdgesList) > 0:
if action >= len(outEdgesList):
reward = -5 # Penalità se l'azione non è valida
done = True
self.addVehicle()
break
else:
self.optimalRoute.append(outEdgesList[action])
traci.vehicle.setRoute(self.current_ego, [current_road, outEdgesList[action]])
action_applied = True
if current_road != "":
current_dist = traci.simulation.getDistanceRoad(current_road, 0, endEdge, 0, False)
if reward == 0:
if current_dist < self.prev_dist:
reward = 1 # Ricompensa per un percorso efficiente
else:
reward = -1 # Penalità per un percorso inefficiente
self.prev_dist = current_dist
return self.edges.index(current_road), reward, done, {}
else:
return 0, reward, done, {} # Ritorno di default nel caso in cui il veicolo non si trovi su una strada
def addVehicle(self):
if self.ego_idx > -1 and self.current_ego in traci.vehicle.getIDList():
traci.vehicle.unsubscribe(self.current_ego)
traci.vehicle.remove(self.current_ego)
self.ego_idx += 1
self.current_ego = "EGO_" + str(self.ego_idx)
self.optimalRoute = [startEdge]
traci.vehicle.add(self.current_ego, baseRoute)
traci.vehicle.subscribe(self.current_ego, (
tc.VAR_ROUTE_ID,
tc.VAR_ROAD_ID,
tc.VAR_POSITION, tc.VAR_SPEED,
))
self.prev_dist = traci.simulation.getDistanceRoad(startEdge, 0, endEdge, 0, False)
def addRandomTraffic(self):
num_vehicles = 50000
depart_time = 30
routes = ["r_0", "r_1", "r_2"]
start_edges = ["B1", "E_0", "G3"]
for i in range(num_vehicles):
route_id = random.choice(routes)
start_edge = random.choice(start_edges)
depart = depart_time * i
traci.vehicle.addFull(f"vehicle_{i}", f"{route_id}", depart=depart, departPos="random")
ray.init()
algo = ppo.PPO(env=RoutePlanner, config={
"env_config": {},
"num_workers": 0
})
# Lista per tracciare il reward medio degli episodi
episode_rewards = []
while True:
res = algo.train()
episode_rewards.append(res["episode_reward_mean"])
# Stampa il conteggio di quante volte la macchina è arrivata a destinazione durante l'episodio corrente
print("Numero di volte che la macchina è arrivata a destinazione durante l'episodio:", RoutePlanner.destination_reached_count)
# Reimposta il contatore alla fine di ogni episodio
RoutePlanner.destination_reached_count = 0
# Traccia la curva di apprendimento ogni 10 iterazioni
if len(episode_rewards) % 10 == 0:
plt.plot(episode_rewards)
plt.xlabel('Episodi')
plt.ylabel('Reward medio degli episodi')
plt.title('Curva di apprendimento')
plt.show()
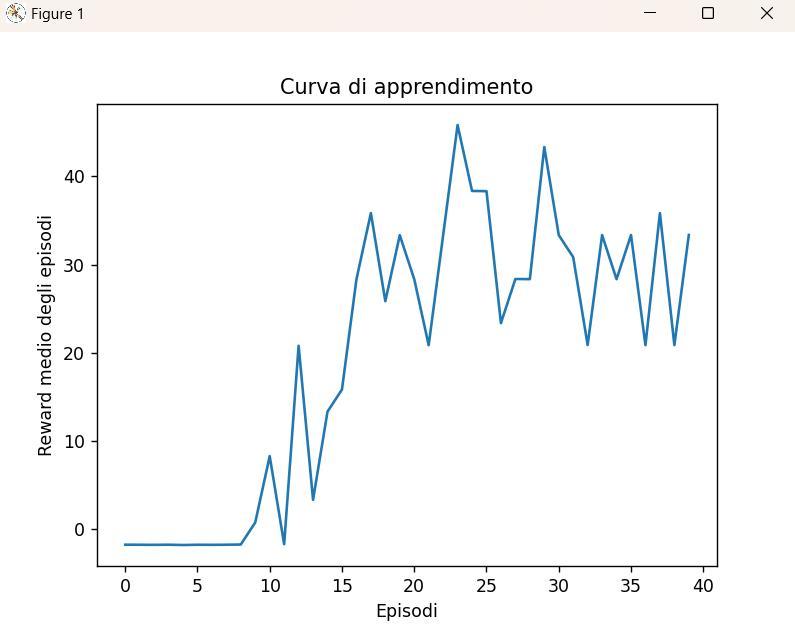
Buongiorno, sto facendo un lavoro universitario su python per un progetto di un ruote planner. Quindi ho scritto un codice per generare veicoli autonomi e il traffico. Tramite il deep reinforcement learning e quindi tramite i reward che vedete nel codice, il sistema dovrebbe imparare e far raggiungere al veicolo autonomo la destinazione dopo varie iterazioni avendo trovato il percorso ottimale. Il nostro problema è che i valori del reward medio che otteniamo a video una volta che raggiunge il massimo non si stabilizzano ,ma continuano ad oscillare, in pratica non arriva a convergenza e non capiamo il perché. Abbiamo provato a cambiare i reward (ad esempio nel codice al momento “definitivo” abbiamo reward di arrivo a destinazione 10000 e gli altri riscalati tra 1 e 10) eppure oscillano sempre i valori. Per di più ci stampa reward medi tra i 20 e i 40 e avendo posto reward arrivò 10000 non capiamo dove prende tutte ste penalità. (O meglio ho provato a capire anche questo, abbiamo inserito un contatore per le iterazioni e abbiamo visto che stampa il reward medio ogni 4000 veicoli, ma arrivano a destinazione solo in media 15 veicoli ecco perché il valore risulta così penalizzato, ma a quel punto la domanda è perchè non arrivano tutti?). Il reward esagerato di arrivo a destinazione era proprio una mia idea per spingere i veicoli ad arrivare sempre eppure non succede. In conclusione i problemi che abbiamo sono:1) il valore non converge mai,2) i veicoli non arrivano sempre. Ovviamente parlo dopo tante iterazioni è normale che all'inizio non accada. Noi siamo studenti di ingegneria meccanica e di sta roba non capiamo un tubo, ci siamo ritrovati in questo nuovo corso di cui non abbiamo le basi. Per favore se potreste dirci un comando, un errore o un qualsiasi cosa per risolvere i nostri problemi vi ringrazierei molto. Arrivederci, attendo risposta. Grazie.