JDBC (Java Database Connectivity) è uno standard di comunicazione, più precisamente un driver, che si traduce in una libreria java il cui intento è stabilire una connessione ad un qualunque tipo di DBMS (Database Management System).
Trattandosi di un prodotto oramai riconosciuto come standard è stato fortemente integrato nelle java lib e per questo viene utilizzato come base per lo sviluppo di nuovi framework, la cui implementazione sfrutta proprio queste librerie. Appare quindi immediata la necessità di un componente condiviso da tutte le architetture RDBMS (DBMS di tipo relazionale) e JDBC stesso, ossia ODBC (Open Database Connectivity): un driver universalmente implementato dalle basi dati indipendentemente dal linguaggio d'implementazione.
Questo articolo intende esplicare le funzionalità di JDBC indicando le alternative di connessione più performanti
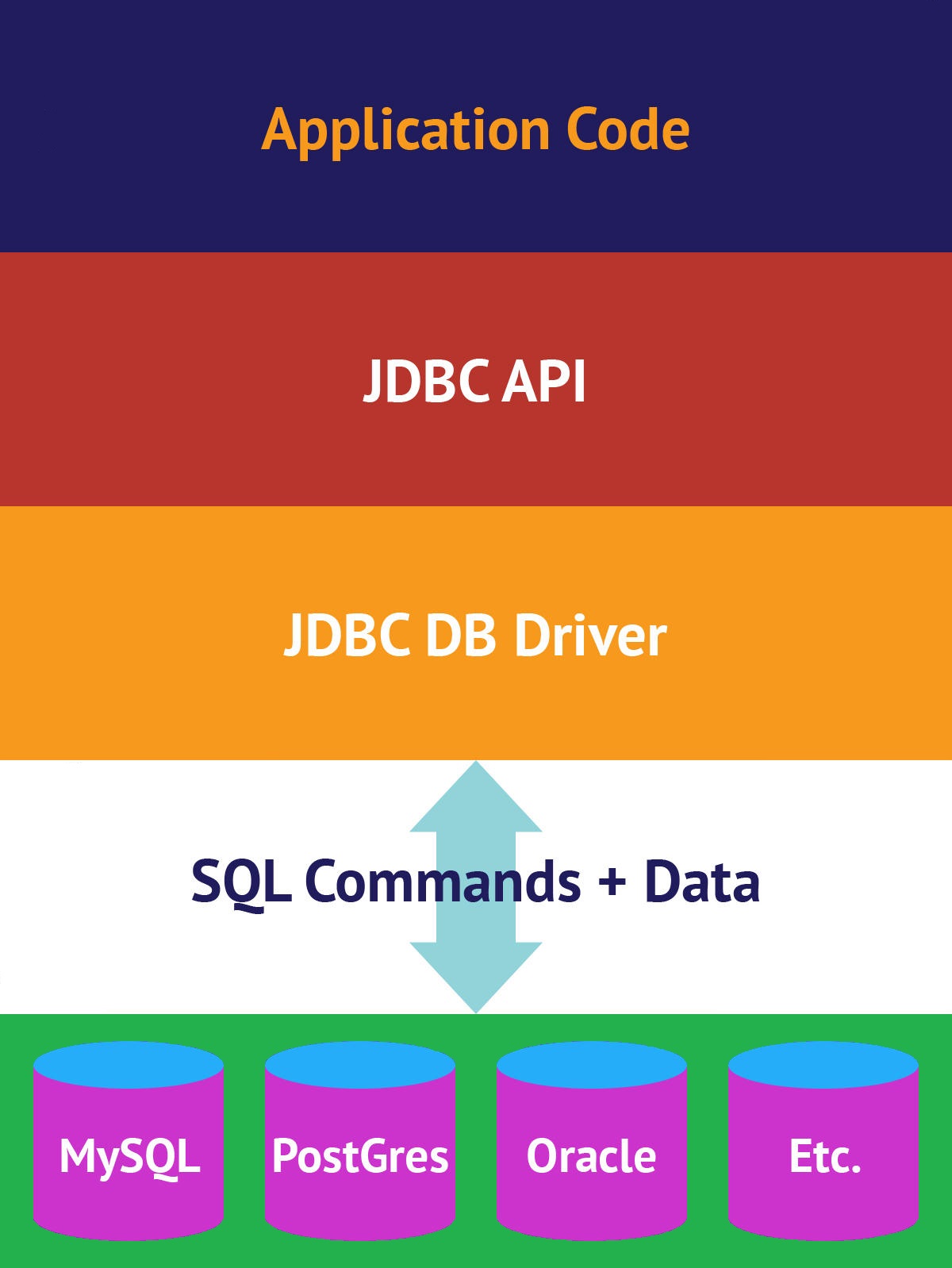
Connessione al DB con JDBC
JDBC offre 2 metodologie di connessione ad una base dati: una più semplice ma non personalizzabile né ottimizzabile ed un'altra che, imponendo uno step di configurazione in più, è da preferire.
La versione semplificata vede l'utilizzo dell'oggetto DriverManager che implica come primo requisito il recupero dell'url di connessione al DB formattato secondo lo standard jdbc. L'url di connessione varia a seconda del client DB da interrogare, vediamo un esempio per MySQL ed Oracle Express:
- MySQL: jdbc:mysql://localhost:3306/test
- Oracle Express (XE): jdbc:oracle:thin:@localhost:1521:xe
Analizzando l'URL di connessione potremmo dividerlo in 3 parti:
- jdbc:mysql:// prefisso standard per le connessioni MySQL
- localhost:3306 nome del server e porta che ospita il DB
- test nome dello schema a cui fare riferimento
Volendo analizzare l'URL Oracle avremo invece:
- jdbc:oracle:thin:@ prefisso standard per le connessioni Oracle
- localhost:1521 nome del server e porta che ospita il DB
- xe suffisso di default per specificare la versione Express di Oracle
Successivamente dovremo specificare sia username che password per stabilire la connessione. Vediamo quindi come ottenere l'oggetto Connection tramite il DriverManager:
String url = "jdbc:mysql://localhost:3306/test";
String username = "user";
String password= "passw";
Connection conn = DriverManager.getConnection(url,username,password);
Fin qui tutto molto semplice. Naturalmente per aderire ad un minimo standard di sicurezza e pulizia del codice le credenziali non saranno certo messe in chiaro nel codice ma come minimo caricate da un file esterno o come variabili d'ambiente/sistema, così da poterle facilmente aggiornare in caso di modifica delle credenziali del nostro DB. Una nota però: con la sintassi appena mostrata il metodo getConnection() farà in modo tale da effettuare in automatico la ricerca di un driver di connessione al client DB specificato. Qualora ovviamente mancasse andrebbe in errore, ecco perché lo si può specificare nel seguente modo, subito prima di ottenere la connessione:
Class.forName("com.mysql.jdbc.Driver");
Vediamo adesso come connetterci ad un database tramite l'oggetto DataSource, indubbiamente una scelta ottimizzata e più personalizzabile.
Una volta introdotti i framework quali spring, hibernate e quindi il meccanismo di Dependency Injection (DI) non ha più alcun senso continuare ad usare il DriverManager in quanto il framework ci fornisce in autowiring un'istanza del nostro DB sulla base delle configurazioni effettuate: altro motivo per studiare sin dal principio il DataSource con maggiore attenzione.
String url = "jdbc:mysql://localhost:3306/test";
String username = "user";
String password= "passw";
DataSource ds= new MysqlDataSource();
/*DataSource ds= new OracleDataSource(); Esempio di implementazione per Oracle*/
ds.setURL(url);
ds.setUser(username);
ds.setPassword(password);
Connection conn = ds.getConnection();
Piuttosto semplice, ma per ora non abbiamo sfruttato alcun beneficio messo a disposizione dal DataSource.
Le Implementazioni del DataSource
Come notato dal precedente codice l'interfaccia DataSource ha differenti implementazioni che variano a seconda del client DB da utilizzare. Abbiamo anche già accennato alla possibilità di gestire i dati di connessione tramite variabili o file esterni facilmente modificabili, così da favorire manutenzione software o migrazione su altro genere di piattaforme. Quello che ancora dobbiamo vedere è la reale utilità del DataSource rispetto al DriverManager e cosa offre un'implementazione rispetto ad un'altra. La prima cosa da sapere è che un dataSource è una legenda, un semplice archivio dei dati di cui abbiamo bisogno per effettuare la connessione al DB. Che si tratti di un file di sistema, un gruppo di variabili o un qualunque altro file di configurazione è sempre un DataSource. Un esempio molto noto è individuabile nei file di configurazione di un qualunque Servlet Container (tipo Apache Tomcat) o Application Server (tipo Wildfly o JBoss). Ognuno di questi ha infatti un file di configurazione che gestisce in formato xml i suddetti dati. Essendo quindi configurabile a livello sistemistico è persino possibile deployare sul proprio server/piattaforma di produzione una propria versione implementativa del DataSource. Così facendo, in un contesto Enterprise o in presenza di un framework è facilmente ottenibile mediante Dependency Injection un'istanza del proprio DataSource già popolata con url, username, password o qualunque altro parametro configurato. In assenza di un qualunque tipo di meccanismo di iniezione delle dipendenze è comunque facile recuperare l'istanza al proprio DataSource custom già deployato:
Context ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("jdbc/myDB");
Con queste pochissime righe è possibile popolare un DataSource mediante l'implementazione deployata sul proprio server / tomcat / wildfly tramite una ricerca che usa come chiave quello che viene definito JNDI name...
Una volta viste queste poche righe (o le equivalenti in caso di Spring e simili) appare immediato non solo il risparmio di codice ma la sua stessa riusabilità: non dovremo né salvare in memoria le credenziali di accesso né bloccare a codice un'implementazione del nostro DataSource e potremo quindi cambiare il tutto lato server con il minimo sforzo e far riflettere le modifiche senza dover rideployare il nostro applicativo.
Funzionalità Avanzate di JDBC
Veniamo ora alle funzionalità quasi mai sfruttate dagli sviluppatori ma che più andrebbero studiate. Tramite le implementazioni del DataSource abbiamo a nostra disposizione alcune funzionalità che il DriverManager non offre:
- Gestione di un pool di connessioni
- Gestione di una transazione distribuita
Tramite alcune conoscenze sistemistiche è possibile deployare un DataSource in maniera tale che le connessioni da esso prodotte tramite il metodo getConnection vengano gestite in pool, ossia tramite un meccanismo ottimizzato che gestisce accessi /disconnessioni di sessione in modo più efficiente. Questo meccanismo gestisce le richieste in ingresso di una nuova connessione al pari di un bilanciatore: se è disponibile una conessione che soddisfi la richiesta la fornisce, se invece non sono disponibili connessioni ne creerà una nuova. Tutto ciò semplicemente deployando un particolare tipo di dataSource detto ConnectionPoolDataSource insieme ad una sua implementazione. Volendo è possibile, dopo aver deployato il DataSource, registrare una o più implementazioni custom tramite il seguente codice, così da poterlo sfruttare in seguito:
com.my.personal.ConnectionPoolDataSource cpds = new com.my.personal.ConnectionPoolDataSource();
cpds.setServerName("personal");
cpds.setDatabaseName("MYDB");
cpds.setPortNumber(9090);
cpds.setDescription("Personal description of my DataSource");
Context ctx = new InitialContext();
ctx.bind("jdbc/pool/personalDB", cpds);
Naturalmente per questo esempio abbiamo inventato un ipotetico ConnectionPoolDataSource custom ed abbiamo settato alcuni parametri (i principali) solo a scopo illustrativo. Con le ultime 2 righe di codice mostrate l'intento è di registrare la risorsa appena creata. Per recuperare la connessione dal pool ci basterà riutilizzare il codice mostrato nel paragrafo precedente che effettua la lookup tramite il JNDI name. Una nota da ricordare nel caso di utilizzo di un pool di connessioni è di chiudere la connessione nel finally (o di immettere la Connection come risorsa gestita dal try-with-resources come mostrato nel prossimo esempio), cosa che però va universalmente rispettata.
Per poter usufruire poi delle transazioni distribuite il processo è davvero simile a quello seguito per il pool di connessioni, solo che il tipo di DataSource da deployare è differente.Dovremo infatti deployare un XADataSource ed un oggetto che lo implementi. Naturalmente vi sono anche implementazioni predisposte sia per il pool di connessioni che per le transazioni distribuite. Ciò di cui c'è da tener conto per queste ultime è che non dovremo mai fare ricorso a chiamate del tipo commit, rollback o setAutoCommit(true) sul nostro oggetto di tipo Connection.
Interrogazioni al DB con JDBC
Vediamo adesso come effettuare delle query.
JDBC opera seguendo questi step:
- Stabilire una Connection al DB
- Preparazione di uno Statement
- Settaggio dei parametri dello Statement (opzionale in base alla nostra query)
- Esecuzione dello Statement
- Elaborazione dei risultati
Il punto 1 era indubbiamente il più complesso a livello teorico; il punto 2 è possibile eseguirlo tramite un semplice Statement oppure tramite un PreparedStatement. Lo Statement classico è meno performante, ha una sintassi meno pulita e non copre da possibili SQL Injection;
per maggiori info a riguardo leggere il seguente articolo: https://www.iprogrammatori.it/articoli/cyber-security/art_sql-injection-cosa-sono-come-difendersi-consigli-utili_1657.aspx
Ecco perché è sempre consigliato utilizzare il PreparedStatement e vedremo solo quest'ultimo. La preparazione di uno di questi Statement implica 2 semplici istruzioni in cui otteniamo un'istanza dell'oggetto e poi settiamo la query da eseguire. Successivamente dobbiamo, qualora la nostra query specifichi dei parametri quali ad esempio WHERE conditions, eseguire il passo 3 settando ogni parametro col giusto valore. Lo Statement viene poi eseguito ed il risultato è un oggetto di tipo ResultSet che va processato in modo ciclico sulla base del numero di righe(record del DB) restituiti dalla query.
Analizziamo quindi una versione completa di connessione al DB immaginando di avere un DataSource deployato del tipo che preferiamo. Per l'esempio seguente si è scelto di immettere tutti gli oggetti Closeable nel try-with-resources; questa prassi non è sempre utilizzata ma è un approccio consigliabile onde evitare di gestire male la chiusura dei vari stream. Capita spesso infatti che si tenti di chiudere questi oggetti (Statements, Connection e quindi tutte le interfacce che estendono la Closeable o la AutoCloseable) nel corpo del try o nel catch. Questa cosa è scorretta in quanto l'unico ed il solo posto dove si dovrebbero chiudere gli oggetti Closeable è nel finally, dacché verrà sempre eseguito. Se si sceglie di utilizzare un try-with-resources che gestisce in automatico tutte queste risorse la sintassi è più compatta ma meno leggibile. Se invece si sceglie di chiudere ogni stream nel finally allora è possibile chiudere manualmente l'oggetto o ricorrere al metodo closeQuietly della classe org.apache.commons.io.IOUtils visto che la dipendenza di appartenenza (commons-io) è spesso inclusa nei progetti. Supponendo di avere quindi il nostro DataSource, vediamo un esempio di connessione e successivamente arricchiamolo con le varie query:
String username = "user";
String password = "passw";
String query = ""; // nei prossimi esempi modificheremo questa query in base all'operazione da effettuare
try(Connection conn = ds.getConnection(username, password);
PreparedStatement pstmt = conn.prepareStatement(query);) {
// elaborazione dei punti 3, 4, 5 che variano in base alla query
} catch(Exception e) {
e.printStackTrace();
}
Mostriamo adesso un esempio per ognuna delle operazioni CRUD (Create, Read, Update, Delete):
public void create(String nome, int eta) {
String query = "INSERT INTO PERSONE (NOME, ETA) VALUES (?,?)";
try(Connection conn = ds.getConnection(username, password);
PreparedStatement pstmt = conn.prepareStatement(query);) {
pstmt.setString(1, nome);
pstmt.setInt(2, eta);
pstmt.executeQuery();
} catch(Exception e) {
e.printStackTrace();
}
}
public void read(int id) {
String query = "SELECT * FROM PERSONE WHERE ID = ?";
try(Connection conn = ds.getConnection(username, password);
PreparedStatement pstmt = conn.prepareStatement(query);) {
pstmt.setInt(1, id);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
Persona p = new Persona();
p.setId(rs.getInt("ID"));
p.setEta(rs.getInt("ETA"));
p.setNome(rs.getString("NOME"));
}
} catch(Exception e) {
e.printStackTrace();
}
}
public void update(int id, String nome, int eta) {
String query = "UPDATE PERSONE SET NOME = ? , ETA = ? WHERE ID = ?";
try(Connection conn = ds.getConnection(username, password);
PreparedStatement pstmt = conn.prepareStatement(query);) {
pstmt.setString(1, nome);
pstmt.setInt(2, eta);
pstmt.setInt(3, id);
pstmt.executeUpdate();
} catch(Exception e) {
e.printStackTrace();
}
}
public void delete(int id) {
String query = "DELETE FROM PERSONE WHERE PKID = ?";
try(Connection conn = ds.getConnection(username, password);
PreparedStatement pstmt = conn.prepareStatement(query);) {
pstmt.setInt(1, id);
pstmt.executeUpdate();
} catch(Exception e) {
e.printStackTrace();
}
}
Come si può notare per qualunque tipo di query, fatta eccezione per le letture da DB, viene utilizzato il metodo executeUpdate che come parametro di ritorno restituisce un intero che indica il numero di righe impattate. Il metodo next appartenente al ResultSet invece cicla i record restituiti: nel dettaglio esso, partendo da un indice precedente a qualunque record restituito, restituisce l'elemento successivo. Durante la prima iterazione quindi processa il primo record e così via. Altra particolarità è che, durante la fase di settaggio dei parametri dello statement, l'indice posizionale parte dal numero 1, non dallo zero canonico.
Qualora la nostra query di tipo Read restituisca un semplice parametro e non un intero record, come nel caso di una ipotetica count, per processare il ResultSet ci basterebbe, invece del ciclo while, utilizzare un codice del tipo:
if (rs.next()) {
int numberOfRows = rs.getInt(1);
} else {
// la query non ha restituito alcun tipo di risultato
}